最近在分析一个程序卡死的问题,没有任何的输出,通过堆栈定位在tcmalloc中,没有任何头绪,进一步分析之后,发现了一个奇怪的bug。
先来看关键堆栈
#0 0x00002b54d4c04ca9 in syscall () from /lib64/libc.so.6
#1 0xo002b54cf085466 in base::internal::SpinLockDelay(std:atomic<int>*, int, int) () from /tmp/.mount ecdcBs3cbg/usr/lib/libtcmalloc and profiler.so.4
#2 0x0002b54cf08534d in SpinLock:SlowLock()()from/tmp/.mount ecdcBs3Cbg/usr/lib/libtcmalloc and profiler.so.4
#3 0xo002b54cf079961 in tcmalloc::CentralCacheLockAll() () from /tmp/.mount_ecdcBs3cCbq/usr/lib/libtcmalloc_and profiler.so.4
#4 0x00002b54d4bd18fc in fork () from /lib64/libc.so.6
#5 0x00002b54bfcc6066 in boost::stacktrace::detail::addr2line[abi:cxx11](char const*, void const*) () from /tmp/.mount_ecdcBs3cbq/usr/lib/lib003.so
#6 0xo0002b54bfcc6988 in boost:stacktrace::detail::to_string[abi:cxxll](boost::stacktrace::frame const*, unsigned 1long) () from /tmp/.mount_ecdcBs3Cbg/usr/lib/lib003.so
#7 0x00002b54bfcafda9 in ?? () from /tmp/-mount_ecdcBs3Cbg/usr/lib/lib003.so
#8 0xo0002b54bfcb9ab0 in ennoComDumpStackTrace:ST_Handler(int) () from /tmp/.mount_ecdcBs3Cbq/usr/lib/lib003.so
#9 <signal handler called>
#10 0x0002b54d4bd1990 in fork () from /lib64/libc.so.6
#11 0xo002b54b3a4859f in TclpCreateProcess () from/tmp/.mount_ecdcBs3cbq/usr/lib/libtc18.6.so
#12 0x00002b54b3a15025 in TclcreatePipeline () from/tmp/.mount ecdcBs3Cbg/usr/lib/libtc18.6.so
#13 0x0002b54b3a15b66 in Tel openCommandChannel() from/tmp/.mount ecdcB3Cbg/usr/lib/libtc18.6.so0
#14 0x00002b54b39f425e in ?? () from/tmp/.mount _ecdcBs3Cbg/usr/lib/libtc18.6.so
#15 0x00002b54b39477b2 in TclNRRunCall1backs () from /tmp/.mount _ecdcBs3Cbq/usr/lib/libtc18.6.so
#16 0x00002b54b39494b3 in ?? () from /tm/.mount _ecdcBs3Cbg/usr/1ib/libtc18.6.so
#17 0x0002b54b39fdba9 in Tcl_ FSEvalFileEx () from/tmp/.mount_ecdcBs3cbq/usr/lib/libtc18.6.so
#18 0x00002b54b39fdd28 in Tcl EvalFile () from/tmp/.mount_ecdcBs3cbg/usr/lib/libtc18.6.so从堆栈得知卡在tcmalloc的锁中,其他线程堆栈并无奇怪地方,理论上tcmalloc这种大型内存开源项目一般不会有死锁这种错误,再仔细看,看到比较奇怪的fork ()函数。
查阅相关资料,发现早在2013年有人报告过相似问题,这是非常专业的一次分析(无需细看):
What steps will reproduce the problem?
Use tcmalloc in an environment where threads might call fork. The testcase
attached (test-threadfork.c) is a small example that creates a set of threads and each
thread allocates some memory, fork a allocates more memory.
Run the testcase with a higher number of threads and forks to trigger the issue.
What is the expected output? What do you see instead?
The expect output is to no deadlock occurs in the fork and all children process eventually
finish. The tcmalloc contains a bug that some internal locks are left in a undefined
state between fork, leaving the child process in a deadlock state.
What version of the product are you using? On what operating system?
I tested svn version r190 in a PPC64 and X86_64 Linux environment.
Please provide any additional information below.
The issue is the locks defined at src/static_vars.h, Static::pageheap_lock_ and each
lock from Static::CentralFreeListPadded elements, needs to be in a consistent state
in a forked version of a thread. Currently, some race issues might occurs if the following
scenario occurs:
Thread 1 | Thread 2
calls malloc() |
\_ tcmalloc lock Static::pageheap_lock_ |
| calls fork()
| calls malloc()
| \_ tcmalloc tries to lock the same lock
The same might occur with any lock from Static::central_cache_ elements as well.
A possible solution, presented in patch gperftools-atfork.patch, is register 2 functions
with pthread_atfork to lock all the locks in the parent just prior the fork() call
and to unlock all the locks after the fork() call on both the parent and child. This
patch fixes the above behavior with the testcase.
I didn't on any other platform, so we might need to add guards on non-unix platforms.
I'm accepting suggestions.在github上也有人报告过相似问题,最初的issue报告在栈内存分配上,这种错误已经解决。
目前,有人在堆内存分配上提出了这个问题:
we should phread_atfork around all of our lock(s) (was: LLVM thread(s) hang after fork from the parent process) · Issue #1425 · gperftools/gperftools
官方解释比较晦涩,我简单描述一下问题:
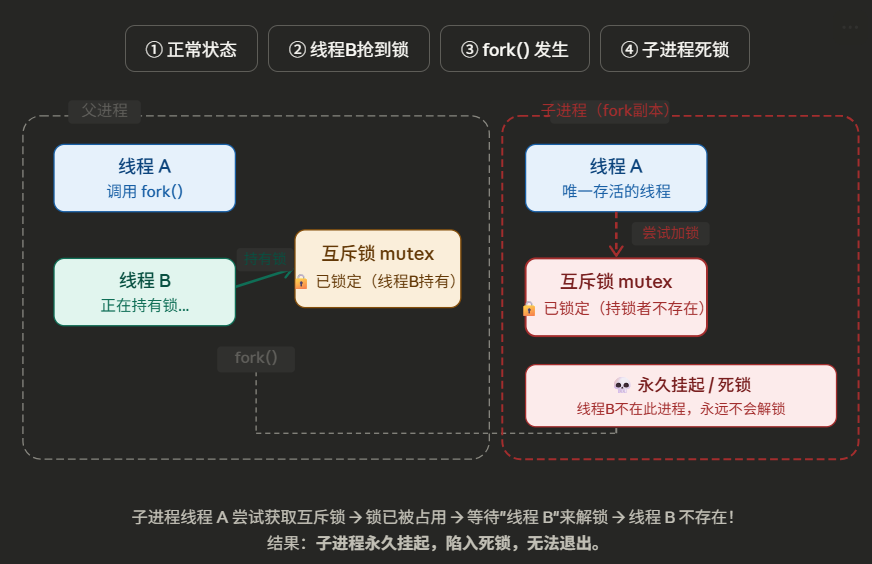
线程A与线程B都是正常运行的线程,在某一时刻,线程B在进行内存操作,于是占用了tcmalloc的锁.
此时线程A进行fork()操作,在linux中fork会将自身与当前内存进行拷贝。
于是在子进程中线程A是唯一线程,但是在当前环境中锁被线程B标记为占用。
当A进行内存操作时,进行等待,永久挂起
这种情况在正常操作下确实不多见,参考了一些网上的解决方案也是将new操作符提前,但是在大型项目中一般无法控制fork函数的调用,因此理论上应对所有锁加上atfork()函数,但是此函数由于过于复杂(疑似)被谷歌内部禁用,对于栈内存,他们已经进行了保护,但是堆内存的保护仍然在开发中。
其实不用fork就行了。
但由于公司业务问题无法避免fork函数的调用。
如何解决?
换成jemalloc大概率能搞定,jemalloc拥有与tc一样的功能和不俗的性能,早期研究过mimalloc也挺不错,如果jemalloc也不能解决,后续我会更新此篇。